




Database Programming with Perl
An Embarrassing Confession
I’d like to think that I’m a reasonably decent Perl programmer now. I’d like to think that I have a good grasp of how to solve relatively common problems in Perl. But, you know, it hasn’t always been this way. Oh no.
A long, long time ago, when I was a tiny little programmer, I worked as a trainee Perl coder and systems administrator for a large database company. Naturally, at a database company, a lot of what we had to do was talking to databases in Perl. As a fresh-faced programmer, the only way I knew to interface with databases was through a command-line SQL client.
I won’t embarrass the company in question by giving away the name of the database, so let’s call this SQL client sqlstar. Very soon I was writing horrendous Perl programs that did things like:
my @rows = `sqlstar $database "select * from $table"`;
for (@rows) {
...
}
Of course, things got terribly confused when we had complex where clauses, and needed to escape metacharacters, and …
my @rows = `sqlstar $database "select * from $table where
$row LIKE \"%pattern%\""`;
The code rapidly got ugly, error-prone, and dangerously unsafe. If someone had decided to search for a value with a double quote in it, I don’t know where we’d have been. But for the most part it worked, so nobody really worried about it.
Looking back on programs like that makes me cringe today. Of course, a better solution is obvious – but only once someone tells you about it. And if nobody tells you about it, you could end up writing horrible code like this until someone does tell you or you get fired.
The Obvious Solution
So in case anyone hasn’t told you yet: there’s a better way. The better way is called the DBI, the DataBase Interface module. It was initially written between 1992 and 1994, long before I was messing about with sqlstar – so I really have no excuse.
You see, there were many problems with my code. Not only was it ugly, susceptible to shell breakage, conceptually wrong, and inefficient, but it tied my code to the particular database engine we were using. Now, given we were a database company, it’s unlikely that we’d ever be using a different database at anytime, but the principle of the thing remains.
Historically, Perl had several different ways to talk to databases; back in the days of Perl 4, the best way to communicate with a database – even better than my horrible command-line utility hack – was to use one of the specially compiled Perl binaries that included functions for driving a database. For instance, there was one called oraperl, which allowed you to write code like so:
$lda = &ora_login("master", $user, $pass);
$csr = &ora_open($lda, "select * from $table");
while (@data = &ora_fetch($csr)) {
# ...
}
This is obviously a bit of an improvement over the code I was writing – it’s a lot more robust, it allows you to do error checking on several different levels, and it saves you a lot of hassle parsing the output of the command-line tool. It’s also more efficient, since everything stays inside the one Perl process, which again reduces the number of “moving parts” and things that can go wrong.
So these things were a good solution for Perl 4, but along came Perl 5 and plug-in modules, and suddenly people found a way to solve one of the big problems with these compiled-in database libraries.
We’ve just seen an example of oraperl, which works great if you’re using Oracle – and, of course, the version of Oracle your Perl was compiled for. If you decide to move your program to Informix, you don’t have much option than to rewrite all your database code; this isn’t very practical, especially if you want to write code that can be deployed to third parties.
The Perl 5 solution was Tim Bunce’s DBI. As well as providing a handy set of functions for all kinds of database access, DBI provides an abstraction layer between the Perl code and the underlying database, allowing you to switch database implementations really easily.
Here’s a little conceptual diagram of how the DBI does its stuff:
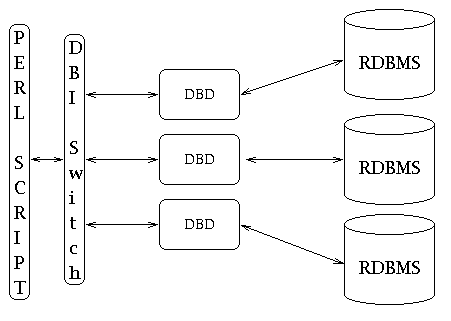 Your Perl program talks to the DBI, and the DBI talks to whichever Database Driver (DBD) is right for your backend database. This means that to use the DBI, you need to have four things:
Your Perl program talks to the DBI, and the DBI talks to whichever Database Driver (DBD) is right for your backend database. This means that to use the DBI, you need to have four things:
- A C compiler to compile the XS code for DBI and the DBD drivers.
- A copy of the
DBImodule compiled and installed. - A copy of the relevant client libraries and header files for the database you want to talk to. For instance, on my Debian system, to talk to mysql, I install the
libmysqlclient10-devpackage. - The relevant DBD library compiled and installed – for example,
DBD::MySQL.
Once that’s all up and working, we can start writing some database code using the DBI.
Using the DBI
To connect to a database with the DBI, we need to first construct a string that identifies the database we want to connect to; this is called a data source name, or DSN. Let’s assume we’re going to be working with a MySQL database called “phonebill.” (Simply because that’s what I was working with yesterday.) The DSN for this is made up of three parts, joined by colons: first, dbi, since that’s what we’re using to get our data; mysql, since that’s the name of the driver we want to use to get it; and phonebill, since that’s the database we’re getting it from.
So, to connect to a database with the DBI, we’d write something like this:
use DBI;
my $dbh = DBI->connect("dbi:mysql:phonebill", $user, $password);
In a lot of cases, you can do without the username and password if you’re connecting as a local user. However, for a serious application, you’ll probably want to create a specific user or prompt for a password.
Now we have connected to the database, DBI returns us a database handle, which is typically stored into a variable called $dbh. (Of course, if you’re connecting to multiple different databases, you may prefer to give it a name that identifies it to a particular database.) Now we have a database handle, and we can use it to make queries.
Making a query in the DBI takes place in three stages. First, you prepare some SQL; then you execute the query; finally, you get the results. Let’s do that now:
my $sth = $dbh->prepare(<<SQL);
select recipient, calldate, calltime, duration
from call
where duration > 60
order by duration desc
SQL
$sth->execute;
my %calls;
while (my @row = $sth->fetchrow_array()) {
my ($recipient, $calldate, $calltime, $duration) = @row;
$calls{$recipient} += $duration;
print "Called $recipient on $calldate\n";
}
# Now do something with the total times here.
Why, you might think, do we have to go through these three stages just to make an SQL query? Isn’t Perl supposed to make things easy? Well it does, but it makes different things easy to what you’re expecting. For instance, suppose you’re inserting a lot of rows into a table. This is precisely the sort of thing you don’t want to do:
<![CDATA[
while (my $data = <FILE>) {
my ($recipient, $date, $time, $duration) = split /:/, $data;
# DON'T DO THIS
my $sth = $dbh->prepare(<<SQL);
INSERT INTO call (recipient, calldate, calltime, duration)
VALUES ("$recipient", "$date", "$time", "$duration");
SQL
# NO REALLY, DON'T DO THIS
$sth->execute;
}
]]>
There are two reasons why this is BAD, BAD, BAD. The first, of course, is that the moment someone comes along with a double-quote in the file, we’re in big trouble. In fact, the moment someone comes along with "; DROP DATABASE; in the table, we’re out of a job.
The second is that it’s really inefficient to set up a statement, execute it, tear it down, set up a statement, execute it, tear it down, and round we go again.
The reason for the disconnect between preparing a statement and executing it is to enable us to use the same statement multiple times with slightly different values; we do this by using what DBI calls “bind parameters” – portions of the SQL that will be replaced later. For instance, the right way to do our mass inserts would be something like this:
my $sth = $dbh->prepare(<<SQL);
INSERT INTO call (recipient, calldate, calltime, duration)
VALUES (?, ?, ?, ?)
SQL
while (my $data = <FILE>) {
my ($recipient, $date, $time, $duration) = split /:/, $data;
$sth->execute($recipient, $date, $time, $duration);
}
Isn’t that just so much neater? We’ve hoisted the statement outside the loop, so it only gets prepared once – much more efficient. We specify the parameters we want bound to the SQL using question marks, and we pass in the values to the execute call.
As an additional bonus, when execute substitutes in the bind values to the SQL, it calls the database handle’s quote method on each one; this is a database-specific method, which escapes any nasty characters like quotes and semicolons in the input, and makes our code safe against the ";drop database attack.
Making Things Easier
But in many cases, the prepare-execute-fetch process is a pain in the neck. Thankfully, DBI provides some easier ways to perform SQL statements; it has some canned methods that do prepare, execute, and fetch in one go.
The first of these is do, which executes a statement when you don’t care about the return value, when you’re not trying to get results back, such as a DELETE:
# Ignore short calls.
$dbh->do("delete from calls where duration < 5");
For SELECT statements, there are a variety of methods that can help out. Perhaps the easiest to use is selectall_arrayref. This returns the results of the SELECT as an array of arrays:
my $results = $dbh->selectall_arrayref(<<SQL);
select recipient, calldate, calltime, $duration
from call
where duration > 60
order by duration desc
SQL
for my $row (@$results) {
my ($recipient, $calldate, $calltime, $duration) = @$row;
...
}
There are many other DBI tricks, too many to go into here; for more information check out the DBI documentation page, or the DBI home page; there’s also Programming the Perl DBI, which was co-authored by the creator of DBI.
Where to from Here?
These days, I actually don’t write very much SQL; there are many more Perlish abstraction layers on top of SQL, such as Tony Bowden’s Class::DBI, the DBIx::RecordSet, DBIx::SearchBuilder and many more.
Additionally, there are some very interesting things going on in the world of database servers – SQLite is a very fast embedded SQL engine which doesn’t require an external server process, and there are Perl bindings to that in the form of DBD::SQLite.
We’ll look at some more of these techniques at a later date, but hopefully this should be enough to get you started using relational databases in Perl … and of course, the most important lesson of this article: don’t worry if you look back at your code after five years and cringe – so do I!
Tags
Feedback
Something wrong with this article? Help us out by opening an issue or pull request on GitHub
